
- Предисловие
- Что позволяет делать dedoc?
- Пример входных данных
- Ограничения библиотеки
- Архитектура библиотеки
- Описание представлений документа
- UnstructuredDocument
- ParsedDocument
- Получаем содержимое текстовых файлов
- Обработка PDF файлов и изображений
- Извлекаем логическую структуру
- Используем библиотеку
- Заключение
Предисловие
Привет, Хабр!
Мы команда разработчиков Института Системного Программирования РАН, занимаемся Computer Vision в обработке электронных документов. Мы разработали open-source библиотеку dedoc, которая помогает разработчикам и дата-сайентистам в пару строк кода читать различные форматы текстовых документов и изображений с текстом, и далее приводить информацию к единой аккуратной структуре.

Зачастую текстовые данные надежно спрятаны в разных форматах файлов. Это могут быть таблицы Excel (XLS, XLSX), документы Word (RTF, DOC, DOCX, ODT) и PDF, сканы и фото документов (PNG, JPG, PDF и пр.) и так далее. Каждый тип файла имеет свои особенности. Есть Open-source библиотеки для чтения файлов, но:
у каждой библиотеки разный формат вывода данных;
с каждой нужно разбираться и настраивать;
при разных форматах файлов нужно объединять библиотеки в общую систему;
сложно расширять функционал;
не везде на выходе присутствует структура текста, аннотации, прикрепленные документы, распознанный с изображений текст (OCR).
Что позволяет делать dedoc?
получать из текстовых файлов различных форматов (DOC, PDF, TXT и т.д.) текст, таблицы, вложенные файлы в едином выходном представлении;
получать информацию о форматировании текста, например, о жирности или размере шрифта;
получать структурированное содержимое для предметных областей, поддерживаемых библиотекой (см. документацию библиотеки dedoc);
стоит выделить в отдельный пункт обработку PDF файлов и изображений – библиотека позволяет извлекать текст и таблицы из подобных файлов, а также делать предобработку изображений;
легко самому прописать обработчик для нового формата файла или предметной области.
Такой инструмент позволил бы решать другие задачи, например, классифицировать документы, искать связи между ними, извлекать определенную информацию. Библиотека подходит для систем анализа больших данных. Например, dedoc используется в Талисман для работы с электронными документами.
Мы начали работать над проектом еще в 2019 году – именно тогда появилась потребность в автоматической обработке разных форматов документов, получения их содержимого и логической структуры (Table of Contents) в едином унифицированном виде. Преимущество нашей библиотеки заключается в ее расширяемости относительно новых форматов файлов и новых предметных областей. Что мы подразумеваем под предметными областями документов? Допустим у вас есть разнородные виды документов (предметные области содержимого): законы, научные статьи, технические задания или НИРы. У каждого такого вида документов есть свои правила, по которым автор пишет содержимое, т.е. он придерживается определенной структуры. В одних типах документов структура жестко фиксированная, например, в законах есть разделы, главы, подглавы, статьи, пункты, подпункты, а в научных статьях структура менее фиксированная, но как правило присутствуют секции с конкретными функциями (аннотация, введение, заключение, используемая литература).

Итак, dedoc – это библиотека с открытым исходным кодом, способная извлекать содержимое текстовых файлов различных форматов в унифицированном представлении и структурировать полученное содержимое в соответствии с конкретной предметной областью документа. Архитектура библиотеки масштабируема, то есть можно добавить обработку новых форматов документов и обработчиков типов структур для новых предметных областей. Библиотека реализована на языке Python и может быть использована непосредственно как библиотека (PyPI), либо в качестве RESTful сервиса.
Для корректной работы библиотеки рекомендуется устанавливать её на ОС Ubuntu 20+, с установкой или использованием на других ОС могут возникнуть проблемы. Если же вы используете другую ОС, то сервис можно запустить в docker контейнере – образ сервиса есть на Docker Hub. Вся необходимая информация по установке библиотеки и её использованию представлена в документации библиотеки dedoc.
Пример входных данных
Как правило, в качестве входных данных мы рассматриваем машинописные ч/б документы, чем лучше качество документа, тем меньше ошибок распознавания текста будем получать на выходе.

Ограничения библиотеки
Понятие “текстовый документ” довольно размытое, особенно когда речь идет об изображениях документов. Библиотека dedoc не является панацеей – она позволяет обрабатывать далеко не каждое изображение, содержащее текст, есть некоторые примеры, где её использовать точно не стоит:
Документы, содержащие рукописный текст. Распознавание рукописного текста – довольно сложная и отдельно решаемая задача, поэтому на данный момент не планируется поддерживать такую функцию в библиотеке.
Документы, содержащие таблицы без границ. Анализ таблиц без границ также является непростой задачей, которая (возможно) будет решаться в будущем.

Изображения текста на ярком, неоднородном фоне. Dedoc предоставляет опцию для повышения качества обработки подобных документов (применение бинаризации), однако слишком яркий фон может помешать отделить основной текст от фона. В таком случае может пострадать результат распознавания текста с изображения.
Документы со сложным макетом. На данный момент в библиотеке нет функционала для умного анализа макета документа, состоящего из 3+ колонок или множества хаотически расположенных блоков текста. Подобные документы могут быть обработаны, но результат распознавания может быть далек от ожидаемого.
Фотографии документов с искривленной перспективой и большим количеством дефектов. Dedoc предоставляет возможность исправить повернутое изображение и устранить некоторые дефекты (пятна) путём бинаризации, однако нет поддержки более продвинутых методов для повышения разрешения изображения или выпрямления искривленных в результате фотографирования документов.
")
Если вы обработаете такие документы библиотекой dedoc, она вернёт какой-то результат, но его качество будет далеко от того, которое вы ожидаете увидеть. Для их обработки советуем использовать какой-либо другой сервис, или заняться разработкой своего сервиса (и использовать dedoc в качестве вспомогательного модуля).
В целом библиотеки dedoc хватает для обработки самой распространенной группы документов – сканированных документов (это примерно 80% от общего объема документов). Мы не рассматриваем специфические сложные документы, иначе теряется автоматизированность обработки.
Архитектура библиотеки
Ниже мы описываем архитектуру библиотеки в общих чертах для того, чтобы продемонстрировать ее возможности. Можно не использовать функции библиотеки в полном объёме, а взять какую-то отдельную часть. Или, наоборот, расширить функционал, добавив свой обработчик на один из этапов обработки файла.
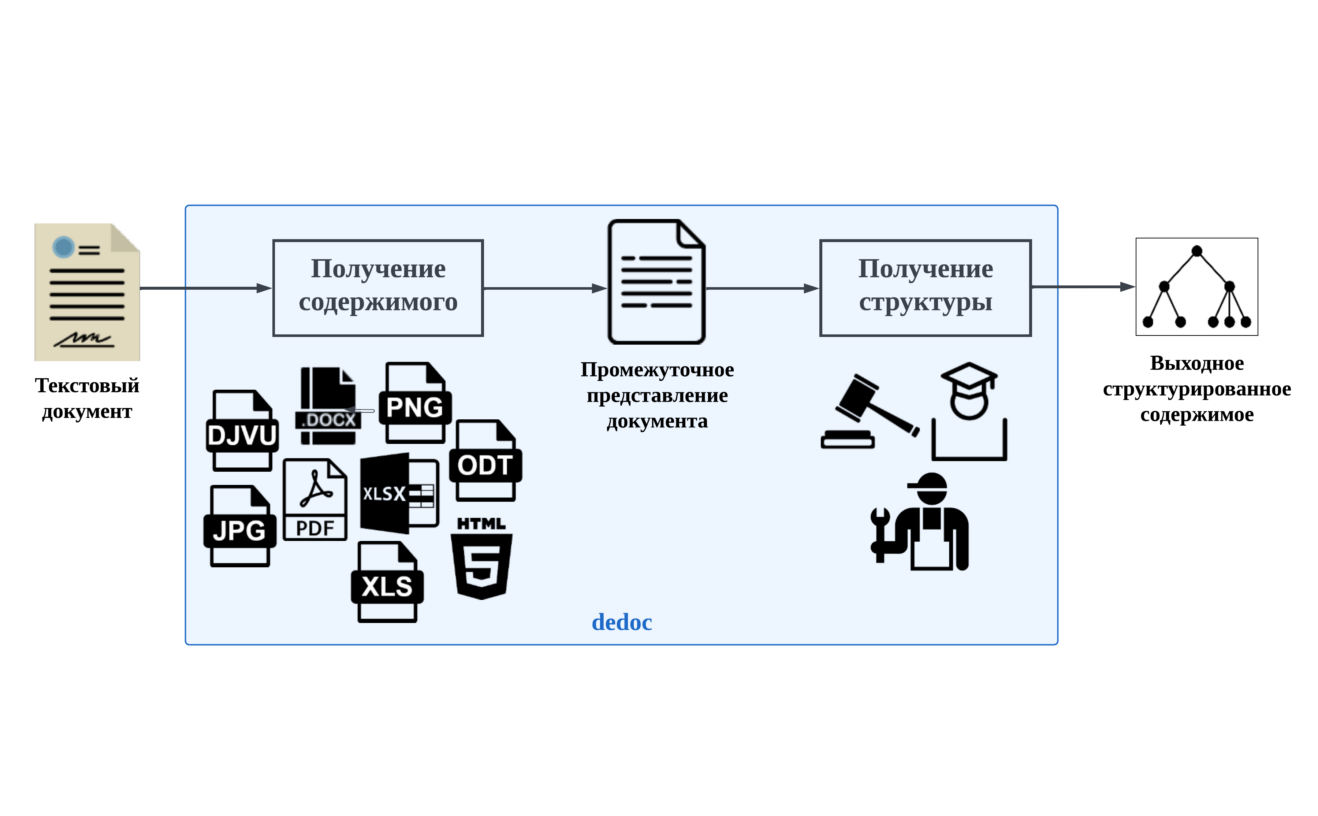
Примерная схема end-2-end обработки документа библиотекой выглядит так:

Рассмотрим каждый этап обработки файла подробнее:
Сначала пришедший на вход файл конвертируется (при необходимости) в формат, поддерживаемый библиотекой для дальнейшей обработки. Конвертируем мы файлы с помощью набора конвертеров (например, DJVU в PDF, RTF в DOCX и т.д.). Этот шаг нужен для того, чтобы не писать слишком много обработчиков извлечения содержимого для всех возможных форматов. Если интересно, что куда конвертируется, можно посмотреть таблицу поддерживаемых форматов.
Потом происходит получение содержимого (чтение) с помощью обработчиков-ридеров. На данном этапе извлекаются из документа:
текст с его форматированием (жирность, отступ, размер шрифта, возможно некоторые структурные теги (заголовок, элемент списка) – то, что удается вытащить из формата документа);
таблицы (содержимое таблиц и структура);
вложенные файлы.
На выходе получается UnstructuredDocument – промежуточное представление, используемое библиотекой (о нем речь пойдет позже). Если интересно, тут перечислены доступные для чтения форматы.
Затем идет извлечение и построение структуры документа из извлеченного на предыдущем этапе содержимого с форматированием. На данном этапе определяется тип каждой текстовой строки документа и ее место (некий приоритет) в выходной структуре (пока у нас есть только структура в виде дерева). На выходе формируется ParsedDocument, о нем также поговорим позже.
Вопрос: В чем смысл разделения обработки на эти этапы?
Ответ: Мы хотим свести к минимуму число обработчиков (ридеров) разных форматов, и хотим структурировать текст документа из общего промежуточного представления. А еще, предоставить возможность использовать по отдельности конвертеры, ридеры, извлекаторы структуры (к этому еще можно добавить извлекаторы вложенных файлов и метаданных документа). И, наконец, если мы хотим получить текст файла конкретного формата, скажем, содержимое презентации в формате PPTX, можно не брать все доступные в библиотеке ридеры, а использовать один, конкретный, предназначенный для презентаций.

Отсюда получается масштабируемость библиотеки – захотели поддерживать новый формат документа или тип структуры, добавляем новую деталь в наш конструктор.
Описание представлений документа
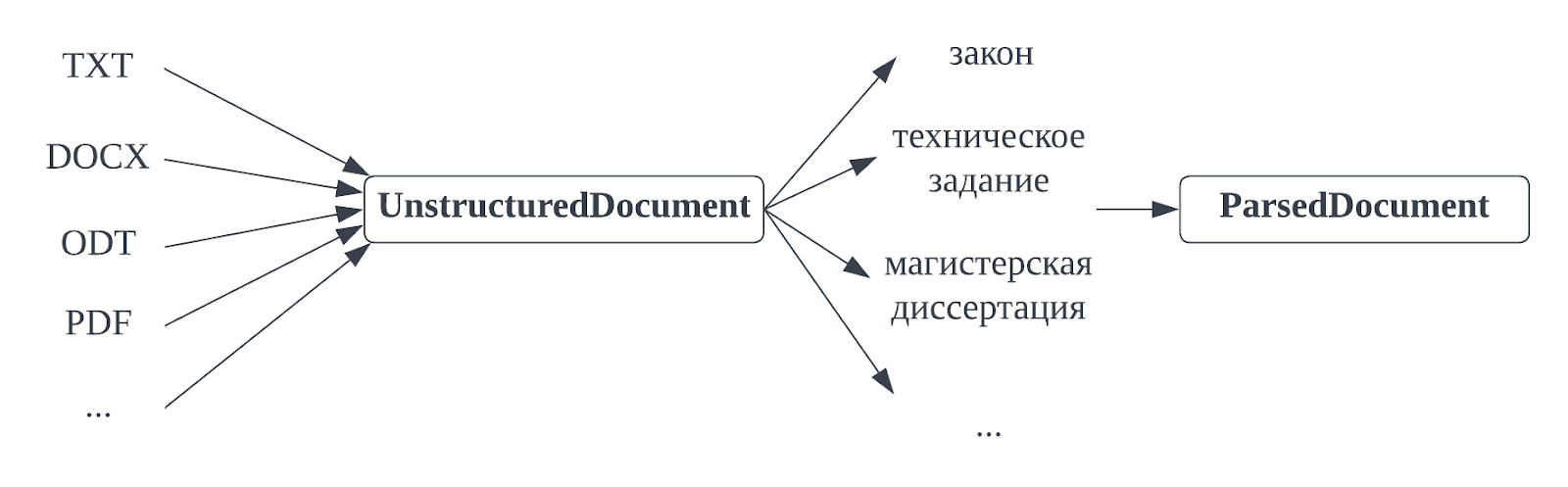
Как было уже сказано, после этапа чтения dedoc получает текстовое содержимое файла в едином промежуточном представлении – UnstructuredDocument. Потом это представление дорабатывается структурированием и в самом конце получается ParsedDocument. Что из себя представляют ParsedDocument и UnstructuredDocument?
UnstructuredDocument
Это представление мы используем для хранения содержимого, которое получают обработчики разных форматов (ридеры). UnstructuredDocument содержит:
lines – текстовые строки документа (LineWithMeta) с информацией о форматировании текста (Annotation), о типах и уровне вложенности строк (LineMetadata);
tables – таблицы документа, каждая таблица является прямоугольной матрицей ячеек (CellWithMeta);
attachments – вложенные файлы, например, картинки внутри презентации или сжатые файлы в архиве;
metadata – информация о документе, например, имя файла, его размер, время создания и т.д.

Текстовые строки в UnstructuredDocument хранятся просто массивом (питоновским списком), поэтому мы считаем, что документ не структурирован. Хотя у строк может храниться информация о структуре документа, например у строки может быть тип “заголовок”. Этого представления может быть достаточно для работы с текстом или таблицами, но если хочется получить дерево документа с типизированными узлами, нужно получать ParsedDocument.
ParsedDocument
Это представление текстового документа итоговое – именно оно сериализуется и возвращается если запускать dedoc как API сервис, именно в нём хранится та самая структура документа в виде дерева со вложенными друг в друга типизированными узлами.
Большинство полей UnstructuredDocument переходят в ParsedDocument почти без изменений – таблицы, метаданные и вложения (они оборачиваются в классы). Сильно меняются текстовые строки – они группируются в параграфы и выстраиваются в иерархическую структуру узлов (TreeNode). Таким образом мы строим древовидную структуру документа на примере решения задачи извлечения оглавления TOC – Table of content.

Для более подробного изучения вспомогательных структур данных можно использовать страницу документации библиотеки.
Получаем содержимое текстовых файлов
Одна из самых интересных и важных частей библиотеки – получение текстового содержимого файлов (этап чтение). Dedoc поддерживает обработку нескольких десятков различных форматов файлов. И да, мы уже несколько раз отправляли вас на сайт документации с описанием поддерживаемых форматов, но здесь мы хотим выделить основные группы форматов и кратко описать их обработку.
Форматы | Описание |
TXT | Возвращаем просто текст |
Офисные форматы | Парсим внутреннее представление формата с использованием вспомогательных библиотек (beautifulsoup, python-docx, python-pptx, xlrd и др.), получаем текст, таблицы вложенные файлы |
HTML, MHTML, EML | Парсим теги, стили и атрибуты, получаем текст и таблицы, из MHTML извлекаем еще и вложения |
Архивы | Извлекаем вложения с помощью вспомогательных библиотек |
PDF и изображения | Извлекаем текст и таблицы, для PDF с текстовым слоем еще и вложения. Для обработки PDF используем библиотеку pdfminer и собственную разработку tabby. Для обработки изображений используем методы компьютерного зрения, в т.ч. движок Tesseract OCR 5 для распознавания текста. |
При просмотре описания обработчиков можно заметить, что в основном их реализация не очень сложная, за исключением последнего пункта. Когда мы доходим до PDF и картинок, нас поджидают бесконечные неприятности и удивительные приключения, которые требуют написания отдельной статьи. Этим мы надеемся заняться в (не)далеком будущем, а пока приведем краткую информацию о том, что происходит при обработке перечисленных форматов.

Обработка PDF файлов и изображений
Как было сказано ранее, при обработке изображений документов мы ограничиваем тип входных данных – не обрабатываем рукописные документы, страницы со сложным макетом и фоном и т.п. Ниже перечисляем, что библиотека dedoc поддерживает и какие задачи нами решены (или находятся в процессе решения):
адаптивная бинаризация изображения;
исправление ориентации изображения документа (поворот на 90°, 180°, 270°);
исправление поворота на небольшой угол (от -45° до 45°);
определение многоколоночности документа (пока поддерживается 1 и 2 колонки);
определение корректности текстового слоя для документов в формате PDF;
распознавание машинописного текста с помощью Tesseract OCR 5;
детектирование и распознавание структуры таблиц с границами с помощью контурного анализа;
определение текста, написанного полужирным шрифтом, на изображении;
склейка строк в параграфы (текстовые блоки);
определение верхних/нижних колонтитулов на изображении документа.
Извлекаем логическую структуру
В англоязычной литературе можно встретить названия для данной задачи TOC (Table of content) extraction или logical structure extraction. На данный момент под логической структурой документа мы подразумеваем следующее:
составными частями структуры мы считаем строки или параграфы текста;
строки текста связаны между собой иерархическим образом: есть строки “более важные”, чем другие, например, заголовок важнее подзаголовка, который, в свою очередь важнее обычного текста;
у каждой строки/параграфа есть тип (например, “раздел”, “глава”, “элемент списка”, “элемент содержания”, “обычный текст”, “колонтитул” и т.п.
Итак, структура документа у нас представляется в виде дерева с упорядоченными типизированными узлами.

Вопрос: Каким образом мы получаем логическую структуру документов?
Ответ:
Для произвольных документов (тип по умолчанию) мы получаем базовую структуру основываясь на оформлении и тексте – выделяем заголовки если у них есть стиль заголовка, элементы списков, если они соответствуют регулярным выражениям.
Для документов из конкретных предметных областей у нас применяется следующая схема:
получение признаков (визуальных, текстовых, статистических) для каждой строки документа, например, размер шрифта или начало текста с цифры/буквы 1., a., 1), a) и т.п.;
классификация строк документа с помощью алгоритма XGBoost на типы, характерные для документов для данной предметной области;
объединение текста и построение иерархии строк на основе правил и регулярных выражений.

Извлечение логической структуры описанным способом реализовано для законов, технических заданий и студенческих работ (ВКР, магистерские диссертации). Подробное описание типов строк и их иерархии описано в документации библиотеки.
Используем библиотеку
На сайте документации библиотеки есть базовый туториал по ее использованию, здесь мы приводим самый простой базовый пример. В примере запускается end-2-end обработка файла любого формата, поддерживаемого библиотекой (файл располагается по пути
file_pathfrom dedoc import DedocManager
file_path = "example.docx"
manager = DedocManager() # создаем класс для универсальной обработки
result = manager.parse(file_path=file_path) # обрабатываем файл
print(result) # <dedoc.data_structures.ParsedDocument>
print(result.to_api_schema().model_dump()) # сериализованное представлениеВот такой простой код способен превратить милый и красивый текстовый документ в наш унифицированный JSON, в котором хранится и содержимое, форматирование и логическая структура:

Заключение
Мы рассказали о нашей разработке dedoc и показали ее возможности для автоматической обработки электронных документов различных форматов и типов. Вы можете использовать библиотеку и настроить ее под ваши нужды, будь то обработка конкретных форматов документов (например, получение содержимого из DOCX), либо вы захотите настроить библиотеку для обработки большого количества форматов и типов документов и получать их результат единым образом в полностью автоматическом режиме. Мы будем рады, кто-то заинтересуется и сможет воспользоваться библиотекой.
Библиотека уже используется как вспомогательный модуль в следующих проектах:
Lingvodoc – система для совместной многопользовательской документации исчезающих языков;
Talisman – платформа для построения предметно-ориентированных систем поиска и извлечения информации;
NeuroDoc – система автоматического распознавания первичных электронных документов.
Также библиотека dedoc позволила нам стать победителями соревнования по извлечению логической структуры из финансовых документов FinTOC 2022.
Часть доступной в настоящий момент функциональности была добавлена в рамках гранта от Фонда Содействия Инновациям (2022-2023).
В качестве дальнейшего направления развития библиотеки мы рассматриваем анализ документов с более сложным макетом, в том числе обработку изображений с таблицами без границ. Также потенциальным направлением может быть улучшение функционала по извлечению логической структуры, например автоматизация добавления обработчика для нового типа структуры (новая предметная область).
На этом мы завершаем наш рассказ, до новых встреч, Хабр!

![[Перевод] Будущее ИИ: зарисовки множества миров](https://web63.ru/wp-content/uploads/2023/11/Perevod-Budushhee-II-zarisovki-mnozhestva-mirov-520x387.jpg)
